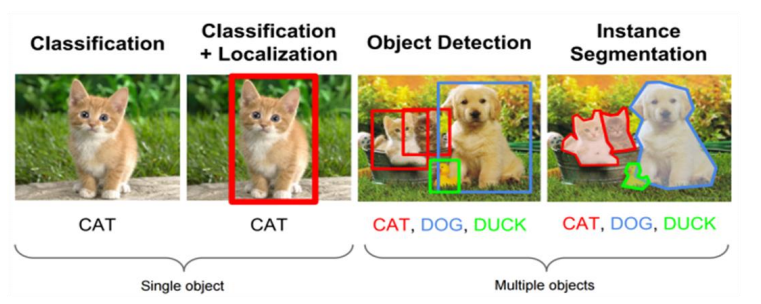
안녕하세요. 데이터 요리사, 루나 입니다. 자율주행 자동차는 실시간으로 주변의 객체를 인지하고, 상황을 판단해서, 차량을 제어하는 엄청난 기술의 총 집합체라고 할 수 있습니다. 이번 글에서는 주변의 객체를 인지하는 기술인 '객체인식(Object Detection) 알고리즘'에 대해서 정리해봅시다. 1 객체인식(Obeject Detection)이란? Multiple object + Classification + Localization 객체인식은 결국 2 category classification 문제: O(찾고자 하는 객체), X(찾고자하는 객체가 아닌 경우) 객체인식 분야의 주요 알고리즘 Proposal 단계 有: RCNN(Region CNN), Fast RCNN, Faster RCNN, RFCNN, M..