안녕하세요. 데이터 요리사, 루나 입니다.

머신러닝은 인간이 한땀한땀 정리해준 수많은 데이터를 학습하기 때문에
학습시 사용하는 데이터가 얼마나 잘 가공되어있느냐에 따라
성능의 차이가 천차만별로 다를 수 있습니다.
데이터가 아무리 많이 수집되어있더라도
똥같은 데이터를 입력하면 똥같은 결과가 나올 수 밖에 없으니까요.

데이터 전처리과정에서 해야할 일은 어떤 데이터를 사용하느냐,
어떤 모델을 사용할 것이냐에 따라 다양합니다.
이미지일 수도 있고, 텍스트일 수도 있고, 수치형 데이터일 수도 있구요.
이번 글에서는 데이터 전처리 과정 중 '결측치 처리 방법'에 대해서 정리해보겠습니다.

| 1 | 결측치 처리란? |
결측치라고 하는 것은 '데이터가 없다'는 것입니다.
일반적인 프로그래밍을 작성할 때 null 값을 참조하게 되면
프로그램이 곧장 죽어버리는 것처럼
데이터에 결측치가 존재한다면 학습이 진행되지 않습니다.
그래서 결측치 처리는 데이터 종류와 상관없이
필수적으로 해주어야하는 데이터 전처리 과정 중 하나입니다.

| 2 | 결측치는 왜 발생할까? |
여러가지 이유가 있겠지만 수집이 제대로 안되서 발생할 가능성이 많겠죠. 설문조사를 통해서 데이터를 수집했는데 몇 가지 항목이 비어있는채로 수집이 되었다던가, 관리하는 과정 중에서 누락된 경우도 있을테구요. 예전에는 수집할 필요가 없었는데 시간이 지나면서 새롭게 수집하기 시작한 항목들이 생기면서 결측치가 발생하기도 할 것입니다. 원인은 알 수 없지만 결론적으로 머신러닝을 하기 위해서는 이런 비어있는 값을 없애주던지 채워주던지 해야한다는거죠.
결측치 처리를 할 때, "왜 결측치가 발생했을까?"를 판단하는 과정은 굉장히 의미가 있습니다. 무작정 특정 값으로 채우는 것이 아니라 의미있는 값으로 변환하여 채워줄 수 있으니까요.
해당 비즈니스 도메인을 잘 알고 있거나, 데이터 수집 절차에 대해서 잘 알고 있는 사람이라면, '이건 의도적으로 비워둔 값이었으니까, 어떤 값으로 대체해서 처리하는 것이 좋겠군' 이런 판단을 할 수 있겠죠?
| 3 | 결측치 처리하기 |
결측치는 없애야합니다. 즉 결측치가 있는 항목을 1)제거 하거나 2) 채워주는 작업을 해야합니다. 머신러닝에 있어서 데이터는 큰 자산이기 때문에 무조건 삭제하는 것은 좋지 않습니다. 하지만 결측치의 비율이 너무 많은 경우에는 오히려 엉뚱한 결과를 초래할 수 있으니 삭제하는 것이 좋구요.
법칙으로 정해져있는 것은 아니지만 보통 결측치가 전체 데이터에 얼만큼 차지하는지 비율에 따라 처리 방법을 달리합니다. 결측치가 10% 미만으로 아주 적은 경우에는 해당 row 값을 삭제하거나 다른 값으로 치환을 합니다. 이 때 치환은 전체 데이터의 평균값이나 최빈값 등을 활용할 수도 있고, 외부 다른 데이터나 다른 컬럼의 값을 기반으로 유추해서 사용할 수도 있습니다.
데이터의 50%이상, 즉 절반 이상이 결측치라면 그 컬럼은 삭제하는 것이 좋습니다. 열(row)을 삭제하면 데이터의 반을 날려버리니 컬럼을 삭제하는 편이 낫겠죠.
그렇다면 위의 경우가 아니라면요? 결측치가 애매하게 10~50%정도 차지한다면 값을 채워줄 수 있는 모델을 만들어서 처리하는 것이 좋습니다. 모델을 만든다는 것은 결측치를 채우기 위한 수식을 만드는거에요. 예를들어서 키, 성별, 체중, 나이 값을 가지고 있는 데이터가 있는데 체중의 몇몇 값이 비어있다고 가정해볼께요. 키와 성별, 나이값을 적절히 조합하면 대략적인 체중의 값을 유추할수 있겠죠! 이런 식으로 비어있는 값을 채워줄 수 있는 수식을 연역적으로 추론해서 만들거나 혹은 머신러닝을 통해 만들어 낼 수 있습니다.
정리해보면 이렇습니다.
- 결측치는 삭제하거나 값을 치환해서 없애주어야한다!
- 결측치는 비율에 따라서 처리 방법을 달리한다!
- 10% 미만이라면: row를 삭제하거나 치환한다.
- 10~50% 사이라면: 모델을 만들어서 처리한다.
- 50% 이상이라면: column을 삭제한다.
| 4 | 결측치 확인 방법 |
데이터에 결측치가 있는지 확인하는 방법 몇가지를 정리해보겠습니다. (파이썬, pandas 사용)
1) 데이터프레임의 info()라는 함수에서 출력하는 Non-Null Count 값이 데이터 전체 개수보다 적다면, 결측치가 존재한다는 것을 알 수 있습니다.
train.info()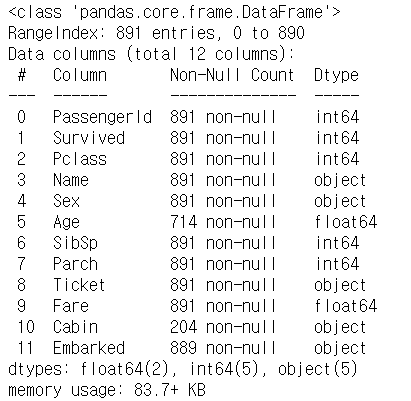
위 데이터는 전체 891개가 있는데 Age, Cabin, Embarked의 Non-Null Count는 891보다 작은 값으로 결측치가 포함되어있음을 확인할 수 있습니다.
2) 데이터프레임의 isnull이라는 함수를 사용해서 확인할 수 있습니다.
train.isnull().sum()isnull()은 True 또는 False를 리턴하기 때문에 결측치가 없다면 모든 값이 False, 즉 0을 반환하게됩니다. 결측치가 존재한다면 True, 즉 1을 반환하게 되구요. 그 값을 sum() 함수를 사용하여 합계를 구하면 해당 컬럼의 총 결측치의 개수를 확인할 수 있습니다.
- 0: 결측치 없음
- 상수: 결측치 개수
| 5 | 결측치 처리방법 |
결측치의 값을 특정 값으로 치환할 경우에는 fillna()라는 함수를 사용해서 치환할 수 있습니다.
아래 코드는 결측치를 중간값(median)값으로 치환하는 예제입니다.
# Filling in the missing value in `Fare` with its median
dataset['Fare'].fillna(dataset['Fare'].median(), inplace=True)내장함수가 아닌 별도의 함수를 만들어서 적용해야할 경우에는 아래처럼 apply를 사용할 수도 있구요.
def family_label(s):
if (s >= 2) & (s <= 4):
return 2
elif ((s > 4) & (s <= 7)) | (s == 1):
return 1
elif (s > 7):
return 0
dataset['FamLabel']=dataset['FamSize'].apply(family_label)컬럼을 삭제할 경우에는 drop()을 사용합니다.
dataset.drop(['Cabin'], axis=1, inplace=True)
※ 만약 데이터 전처리를 PipeLine을 통해 일괄적으로 처리한다면, SimpeImputer 를 사용하여 일괄적으로 값을 처리할 수도 있습니다.
| 함께 보면 좋은 글 |
※ 이 글의 내용을 상업적으로 무단 활용, 편집하는 것은 금지하고 있습니다. 강의, 출판 등 상업적 이용이 필요하신 경우, 문의 바랍니다.
'데이터·데이터전처리' 카테고리의 다른 글
| [데이터 전처리 05] - 데이터는 그냥 합칠 수 있는게 아니다, "데이터 통합" 제대로 정리하기 (0) | 2021.08.13 |
|---|---|
| [데이터 전처리 04] - 데이터가 너무 많아 분석하기 힘들다면? "데이터 축소" (0) | 2021.08.13 |
| 쉽지만 실수하기 쉬운 데이터 분할! - 예비법, 교차검증, 부트스트랩까지 완벽 정리 (0) | 2021.01.27 |
| [데이터 전처리 02] - 머신러닝에서 가장 중요한(?) 데이터 전처리(2) - 이상치(Outlier) 처리 (0) | 2021.01.27 |
| [통계 기초 정리] - 데이터 분석을 할 때 꼭 알아야하는 통계 개념'만' 정리 (0) | 2020.11.23 |