안녕하세요. 데이터 요리사, 루나입니다.

데이터 분석은 다양한 기관에서 수집한 데이터를 하나로 모아서 진행하기도 하고,
동일 기관이라도 여러 개의 파일, 테이블로 나누어서 관리하기 때문에
다양한 소스에 존재하는 데이터를 합치는 작업이 필요합니다.

데이터는 어떻게 합칠 수 있을까요?
데이터 통합에 대해서 알아봅시다.
| 1 | 데이터 병합(merge)과 조인(join) |
- 여러 개의 데이터 파일이 있는 경우, column(열)을 결합 하거나 row(행)을 결합하는 작업
- 기업의 상반기 데이터 A와 하반기 데이터 B가 다른 파일에 저장된 경우, 데이터 A와 데이터 B를 병합하여 분석
- 학생의 국어성적 데이터 A와 수학성적 데이터 B가 다른 파일에 저장된 경우, 데이터 A와 데이터 B를 병합하여 분석

- 새로운 데이터셋을 설정한 key값을 기준으로 기존의 데이터셋과 결합하는 방법
- 학생 기본 정보 데이터 A와 성적 정보 데이터 B가 다른 파일에 저장된 경우, 데이터 A와 데이터 B를 조인하여 분석
| 조인 방법 | 설명 |
| Inner join |
-가장 보편적으로 사용하는 방법으로, key(키)를 기준으로 두 테이블에 같이 존재하는 데이터를 추출
|
| left outer join |
-왼쪽 데이터셋에 있는 테이블의 key를 기준으로 병합
|
| right outer join |
-오른쪽 데이터셋에 있는 테이블의 key를 기준으로 병합
|
| full outer join |
-key를 기준으로 두 테이블에 존재하는 모든 데이터를 뽑아내어 병합
|
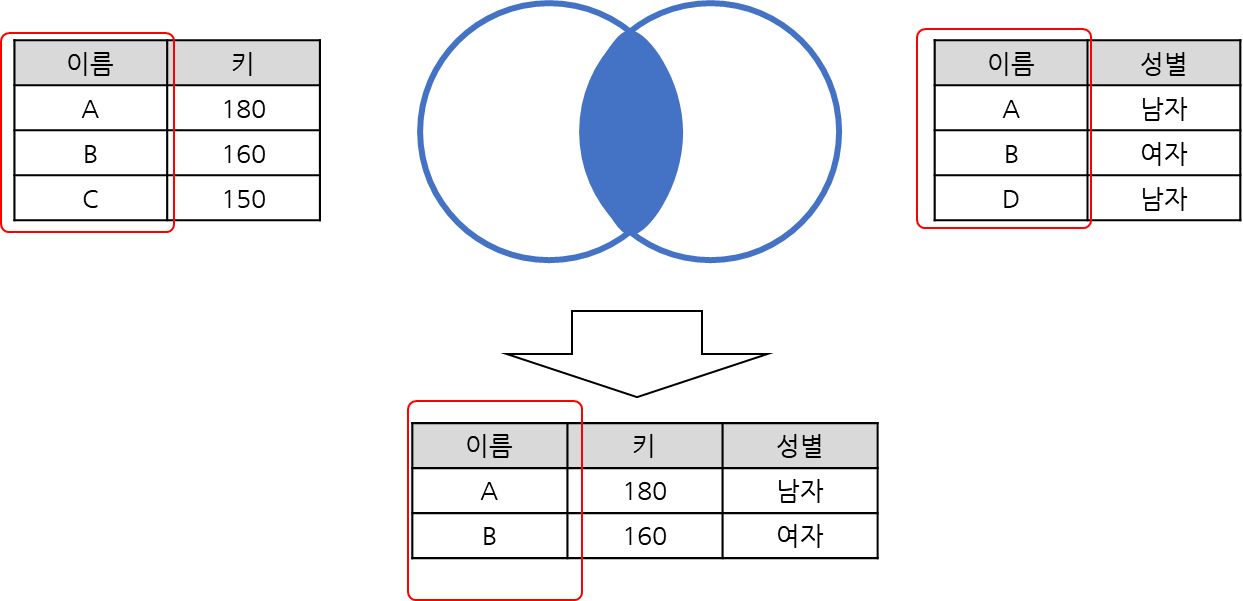


Full outer join: key를 기준으로 두 테이블에 존재하는 모든 데이터를 뽑아내어 병합

| 2 | 데이터 통합 프로세스 |
데이터를 통합하는 방법을 알았다면 사전에 어떤 작업을 진행하는지 데이터 통합 프로세스를 살펴봅시다.

1) 통합할 데이터를 선정했다면 어떤 기준으로 관리할 것인지 체계를 마련해야합니다. 가장 체계의 가장 기본이 되는 것이 바로 2)표준사전 정의 부분입니다. 어떤 언어가 되었든지 간에 뜻이 비슷한 다양한 단어가 존재하고 있기 때문에, 표준사전을 정의하지 않아면 데이터베이스를 사용하는 사람마다 자기 나름의 규칙을 가지고 테이블을 생성하겠죠. 처음에 DB를 구축하는 단계에서도 그렇고, 서로 다른 사전을 사용하는 데이터를 통합할 때에도 그렇고 표준사전을 정의하는 것은 운영과정을 생각했을 때 매우 중요합니다. 표준사전을 정의했다면 3) 중복데이터를 판단해서 같은 데이터는 하나로 4) 통합하여 관리합니다.
| 3 | 데이터 통합과정: 데이터 표준사전 정의 |
공통표준도메인
| NO | 공통표준도메인 그룹명 | 공통표준도메인 분류명 | 공통표준도메인명 | 공통표준도메인 설명 | 데이터 타입 | 데이터 길이 | 저장 형식 | 표현 형식 | 단위 | 허용값 |
| 1 | 금액 | 가격 | 가격N10 | 물건이 지니고 있는 가치를 돈으로 나타낸 것 | NUMERIC | 10 | 9999999999 | 9,999,999,999 | 원 | - |
| 2 | 금액 | 금액 | 금액N15 | 돈의 액수 | NUMERIC | 15 | 999999999999999 | 999,999,999,999,999 | 원 | - |
| ... | ||||||||||
| 5 | 날짜/시간 | 시분초 | 시분초C6 | 시간상의 한 순간을 시, 분, 초로 표기, 시간의 어느 한 시점 | CHAR | 6 | HH24MISS | HH:MI:SS | 시분초 | HH : 00~23, MI : 00~59, SS : 00~59 |
| 6 | 날짜/시간 | 연도 | 연도C4 | 특정한 연(年)을 정하여 표현한 것 | CHAR | 4 | YYYY | YYYY | 연도 | YYYY : 0001~9999 |
공통표준단어
| NO | 공통표준단어명 | 공통표준단어영문약어명 | 공통표준단어영문명 | 공통표준단어 설명 | 형식단어여부 | 공통표준도메인분류명 | 이음동의어 목록 | 금칙어 목록 |
| 55 | 금액 | AMT | Amount | 金額. 돈의 액수 | Y | 금액 | - | - |
공통표준용어
| NO | 공통표준용어명 | 공통표준용어 설명 | 공통표준용어영문약어명 | 공통표준도메인명 | 허용값 | 저장형식 | 표현형식 | 단위 |
| 1 | 가산금액 | 세금이나 공공요금 따위를 납부 기한까지 내지 않은 경우, 원래 금액에 일정한 비율로 덧붙여 매기는 돈의 액수 | ADTN_AMT | 금액N15 | - | 999999999999999 | 999,999,999,999,999 | 원 |
| 4 | 데이터 통합과정: 중복데이터 판단 |
중복 데이터는 인스턴스의 중복이 있을 수 있고, 속성의 중복일 수도 있습니다.
1) 인스턴스의 중복
먼저 인스턴스의 중복이라고 하면, row 기준으로 같은 데이터가 존재하는 것으로 똑같은 학생의 정보가 두 번 들어가 있는 경우에 해당합니다.
이 경우 아래와 같이 중복데이터를 확인하고 제거할 수 있습니다.
# 중복 데이터 확인
df.duplicated()
# 중복 데이터 제거
df.drop_duplicates(inplace=True)2) 속성의 중복
여러 데이터 저장소를 사용하는 데이터 통합하다보면, 특성(feature)명 지정방법이 모호하거나 또는 다른 명칭으로 저장하여 불일치가 발생하여 데이터 세트가 중복되는 경우가 발생합니다. 도메인 지식이 있거나 특성의 수가 많지 않다면 하나씩 확인해볼 수 있지만 쉬운 일은 아닙니다.
중복 속성(Redundant attributes)은 한 데이터의 특성(feature)을 다른 특성(feature) 에서 파생된 값으로 설정 할 수 있는 경우입니다. 아래 데이터에서 키(cm)와 신장(ft), 무게(kg)와 체중(lb)은 사실 같은 속성이죠. 굳이 구분해서 관리할 필요가 없습니다.(물론 성능이나 필요에 따라서 둘을 나눠서 관리해야하는 경우도 있겠지만요.)
| id | 이름 | 키(cm) | 신장(ft) | 무게(kg) | 체중(lb) |
| 1 | Ann | 160 | 5.23 | 50 | 110 |
| 2 | Tom | 180 | 5.90 | 70 | 154 |
| … |
여러 데이터 저장소를 사용하는 데이터 통합하다보면, 특성(feature)명 지정방법이 모호하거나 또는 다른 명칭으로 저장하여 불일치가 발생하여 데이터 세트가 중복되는 경우가 발생합니다. 도메인 지식이 있거나 특성의 수가 많지 않다면 하나씩 확인해볼 수 있지만 쉬운 일은 아닙니다. 중복 속성을 감지하기 위해서 피처간의 상관 분석(Correlation Analysis)을 통해 한 속성이 다른 속성을 얼마나 강하게 의미하는지 측정할 수 있습니다.
- 수치형 데이터: 파어슨(Pearson) 상관계수를 계산하여 평가
- 범주형 데이터: 카이 제곱 검정을 계산하여 평가
- 두 변수 간에 어떤 선형적 관계를 갖고 있는 지를 공분산 또는 변수의 순위 등의 계수를 이용하여 분석하는 분석 기법
- 양의 상관관계: A가 증가함에 따라 B가 증가함(상관계수 > 1)
- 음의 상관관계: A가 증가함에 따라 B가 감소함(상관계수 <1)
- 상관관계 없음: A와 B가 서로 독립적인 관계임(상관계수 =1)

| 함께 보면 좋은 글 |
※ 이 글의 내용을 상업적으로 무단 활용, 편집하는 것은 금지하고 있습니다. 강의, 출판 등 상업적 이용이 필요하신 경우, 문의 바랍니다.
'데이터·데이터전처리' 카테고리의 다른 글
| [데이터전처리 08] - Feature Engineering vs Data Cleansing, 용어 정리 (0) | 2022.02.20 |
|---|---|
| [데이터 전처리 07] - 데이터의 누수"Data Leakage"를 바로 잡자! (0) | 2021.11.30 |
| [데이터 전처리 04] - 데이터가 너무 많아 분석하기 힘들다면? "데이터 축소" (0) | 2021.08.13 |
| 쉽지만 실수하기 쉬운 데이터 분할! - 예비법, 교차검증, 부트스트랩까지 완벽 정리 (0) | 2021.01.27 |
| [데이터 전처리 02] - 머신러닝에서 가장 중요한(?) 데이터 전처리(2) - 이상치(Outlier) 처리 (0) | 2021.01.27 |