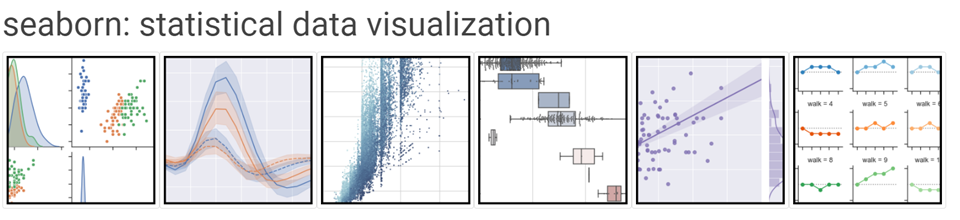
안녕하세요. 데이터 요리사, 루나입니다. Seaborn을 활용한 데이터 시각화 실습과제 2탄입니다. ※ dataset과 과제의 답안은 클래스 수강생을 대상으로 배포합니다. ※ 1 Lineplot(spotify data) 1) 데이터 준비 import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # 도표의 너비(14)와 높이(6) 설정 plt.rc('figure', figsize=(14,6)) df = pd.read_csv("./dataset/spotify.csv", index_col="Date", parse_dates = True) 2) 분석과제 주어진 데이터를 활용하여 5개의 음원에 대한 Line plot 그리기 주어진 데이터를..