안녕하세요. 데이터 요리사, 루나입니다.

어떤 일이든지 내가 해결하고자 하는 것이 무엇인지 분명하게 정의하는 것이 매우 중요합니다.
머신러닝 문제를 정의하기 위해서는 기계가 학습하는 방법에 대해서 알고 있어야합니다.
기계는 어떤 식으로 학습을 할까요?
| 1 | 머신러닝 학습방법 |

기계가 학습하는 방법을 보통 세 가지로 분류합니다. 지도학습, 비지도학습, 강화학습 이렇게요.
여기서 '지도'는 map이 아닌 teach의 개념입니다. 기계에게 답을 가르쳐주느냐, 주지 않느냐에 따라서 크게 지도/비지도 학습으로 나누고 이 둘을 적당히 섞은 준지도학습(Semi-supervised Learning)이라는 개념도 있습니다. 각각의 학습 방법에 대해서 살펴보겠습니다.
1-1. 지도학습(Supervised Learning)

아이들이 처음으로 말을 배울 때를 떠올려 볼까요? 엄마는 아이에게 주변에 있는 인형, 동화책, 그림 카드등 온갖 수단을 동원해서 아이에게 단어를 알려줍니다.
"(책을 보면서) 이건 강아지! 강아지!"
"(산책을 하면서) 어머~ 저기 강아지다!"
"(TV를 보면서) 강아지가 나왔네~~"
아이는 수많은 강아지의 이미지와 실물을 보면서 강아지의 존재에 대해서 배우게 됩니다. 그리고 언젠가 스스로 강아지를 가리키며 "강아지다!"하고 외치게 되죠.
이런 방식으로 학습하는 것이 지도학습입니다. 다시 머신러닝 세계로 돌아가보면 모든 데이터에 정답이 무엇인지 작성해두고, 기계에게 알아서 인식해봐!하고 미션을 주는 방식이죠. 각각의 데이터에 정답을 작성하는 것을 '레이블(label)을 달아준다'라고 이야기 합니다. 기계에게 지도학습으로 강아지를 알려주기 위해서는 수백장의 강아지 사진과 각각의 사진에 '강아지'라고 레이블을 달아주어서 학습을 시키면 됩니다. 지도학습의 성능은 얼마나 많은 데이터를 확보했는지가 중요한데, 각각의 데이터에 정확하게 레이블을 다는 작업이 만만치 않겠죠? 개노가다
대량의 데이터를 확보하는 것도 어렵고, 레이블을 올바르게 달아주는 작업도 굉장히 어렵습니다.
1-2. 비지도학습(Unsupervised Learning)

다시 아이의 세계로 돌아가볼께요. 아이가 레고 블록을 만지작거립니다. 어떻게 하라고 알려주지 않았는데도 똑같은 색깔끼리 차곡차곡 쌓아올리기도 하고, 같은 모양끼리 차곡차곡 쌓기도 하네요.
어떻게 하라고 알려주지 않아도, 스스로 숨은 패턴을 찾아서 블록을 나눕니다. 색깔별로 또는 모양별로... 이런 방식으로 모델을 생성해내는 방식이 비지도학습입니다.
대량의 데이터에 레이블을 달지 않고, 그냥 패턴을 찾아봅니다. 이 사진과 이 사진이 비슷한데? 나름의 패턴을 찾아서 유사한 데이터끼리 묶어내는 과정을 클러스터링, 군집이라고 하는데요. 이 군집 알고리즘이 대표적인 비지도학습의 사례입니다.
1-3. 강화학습(Reinforcement Learning)
강화학습은 알파고가 학습한 방법으로 유명해졌죠. 강화학습은 어린 아이보다는 어른이 학습하는 방법과 유사합니다. 강화학습에서는 보상을 최대화하기 위한 방향으로 모델을 학습해나가는 방식으로 학습합니다.
| 2 | 머신러닝으로 해결할 수 있는 문제 |
머신러닝 방법에 대해 이해가 되었다면 '문제 정의'에 대해서 살펴볼께요.
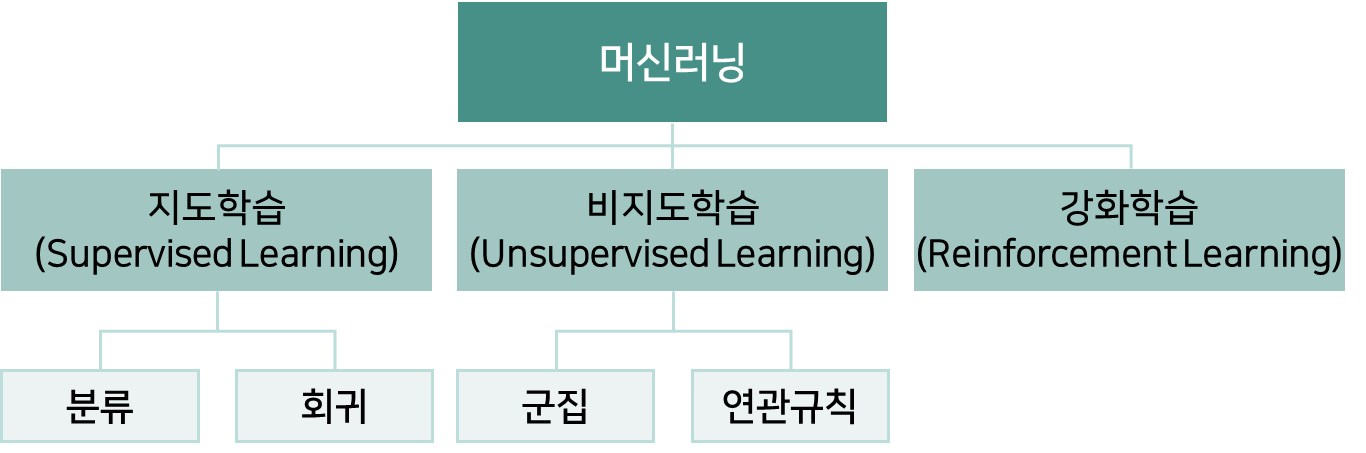
강화학습은 나중에 딥러닝을 정리할 때 다시 살펴보도록 하고, 지도/비지도 학습의 주요 문제 유형에 대해서 보겠습니다. 지도학습의 대표적인 문제 유형은 분류와 회귀입니다. 비지도학습은 군집과 연관분석이구요.
가끔씩 분류와 군집을 헷갈려하시기도 하는데요. 둘 다 전체 데이터를 몇 덩어리로 나눈다는 개념에서는 유사하지만, 분류는 각각의 덩어리가 무엇인지(강아지인지? 고양이인지?) 정확하게 답할 수 있도록 학습을 시킵니다. 반면에 군집은 두 덩어리로 나뉘는데 어떤게 강아지인지? 고양이인지? 정답은 내뱉을 수 없는 거죠. 군집분석에서는 정답을 사람이 데이터를 확인해서 찾아주어야합니다.
머신러닝의 대부분은 '지도학습'이라고 해도 과언이 아닐 정도로 많이 차지하고, 이 중 90%는 '분류'문제라고 할 정도로 분류문제가 차지하는 비율이 많습니다.
| 3 | 문제 유형에 따른 머신러닝 알고리즘 |
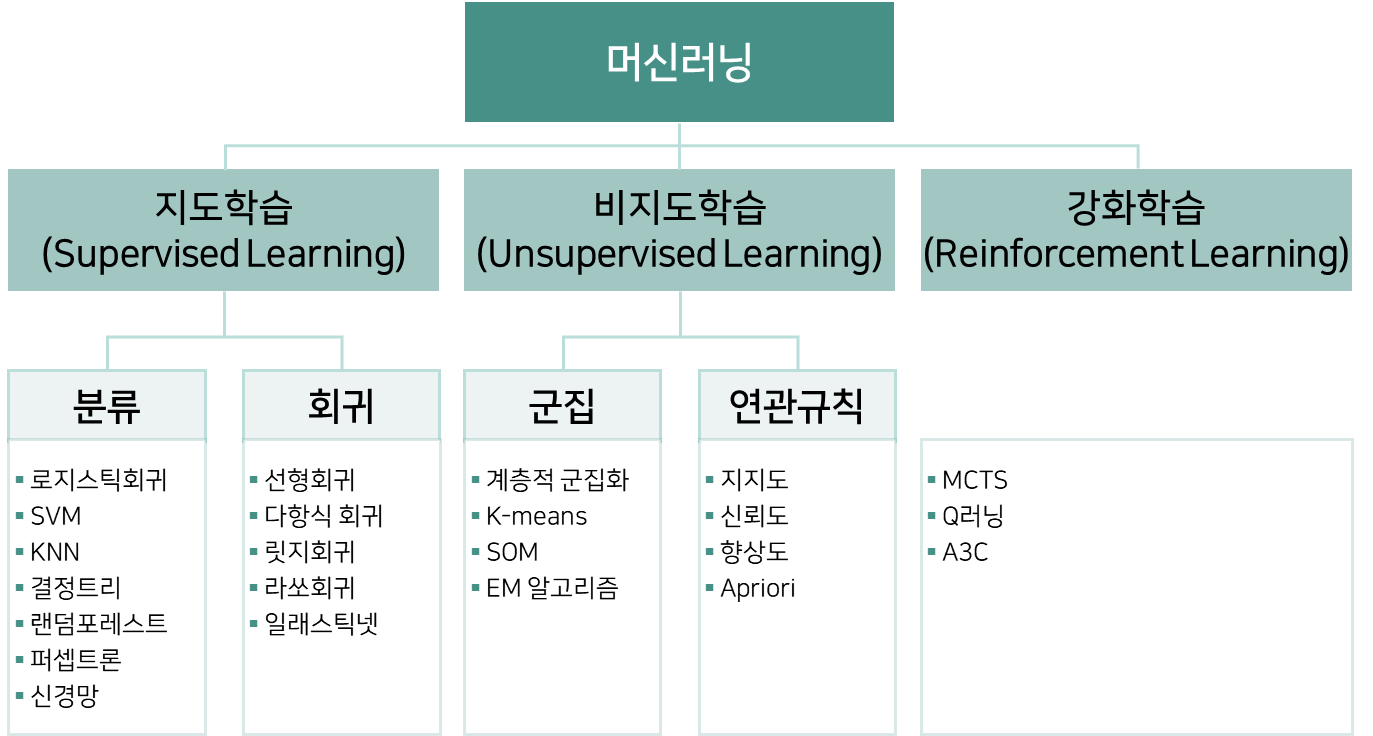
문제를 정의했다면 학습할 때 사용해야할 알고리즘도 선택할 수 있습니다. 대표적인 분류 알고리즘으로 결정트리(Decision Tree), 랜덤포레스트(Random forest) 등이 있습니다. 위의 그림에서는 분류 알고리즘의 대부분은 회귀 알고리즘으로 사용할 수 있습니다. 예를 들어 랜덤포레스트도 RandomForestClassifier(분류기)가 있고 RandomForestRegressor(회귀)가 존재하는거죠. (그림 상으로 분류 쪽으로 정리한 것이니 참고하시길 바랍니다.)
수많은 데이터를 보고 이렇게 문제를 정의할 줄 안다면 머신러닝에서 이미 큰 산을 하나 넘은 것입니다. 인공지능 알고리즘을 살펴보다보면 사람이 어떻게 학습을 해나가는지도 덩달아 이해하게 됩니다. 결국 기계를 사람처럼 생각하게 만들려고 시작한거니 그렇지 않을까 생각해봅니다.
| 함께 보면 좋은 글 |
※ 이 글의 내용을 상업적으로 무단 활용, 편집하는 것은 금지하고 있습니다. 강의, 출판 등 상업적 이용이 필요하신 경우, 문의 바랍니다.
'머신러닝' 카테고리의 다른 글
| 머신러닝 분류 모델의 평가 지표 - 정확도, 정밀도, 재현율, 민감도, F1 스코어 (0) | 2023.07.14 |
|---|---|
| [머신러닝] 분류 알고리즘 한 페이지 정리(로지스틱회귀, SVM, KNN, 결정트리, 앙상블) (0) | 2021.11.30 |
| 머신러닝이란? - 머신러닝 절차, 머신러닝 프로세스 이해하기 (0) | 2020.10.19 |